Table of Contents
OMPL contains a ompl::Benchmark class that facilitates solving a motion planning problem repeatedly with different parameters, different planners, different samplers, or even differently configured versions of the same planning algorithm. Below, we will describe how you can use this class.
For interactive visualization of benchmark databases, please see plannerarena.org.
Writing benchmarking code
Benchmarking a set of planners on a specified problem using the Benchmark class in your own code is a simple task in OMPL. The steps involved are as follows:
- Configure the benchmark problem using ompl::geometric::SimpleSetup or ompl::control::SimpleSetup
- Create a ompl::Benchmark object that takes the problem as input
- Optionally, specify some parameters for the benchmark object using ompl::Benchmark::addExperimentParameter, which is useful when aggregating benchmark results over parametrized benchmarks.
- Add one or more planners to the benchmark
- Optionally add events to be called before and/or after the execution of a planner
- Run the benchmark problem a specified number of times, subject to specified time and memory limits
The following code snippet shows you how to do this. We will start with some initial code that you have probably already used:
Benchmarking code starts here:
Adding callbacks for before and after the execution of a run is also possible:
Processing the benchmarking log file
Once the C++ code computing the results has been executed, a log file is generated. This contains information about the settings of the planners, the parameters of the problem tested on, etc. To visualize this information, we provide a script that parses the log files:
This will generate a SQLite database containing the parsed data. If no database name is specified, the named is assumed to be benchmark.db. Once this database is generated, we can visualize the results. The recommended way is to upload the database to Planner Arena and navigate through the different plots. Planner Arena can also be run locally with the plannerarena script (installed via pip3 install plannerarena). Planner Arena will generate a series of plots, one for each of the attributes described below, showing the results for each planner. BelowBelow we have included some sample benchmark results.
If you would like to process the data in different ways, you can generate a dump file that you can load in a MySQL database:
For more details on how to use the benchmark script, see:
Collected benchmark data for each experiment:
- name: name of experiment (optional)
- totaltime: the total duration for conducting the experiment (seconds)
- timelimit: the maximum time allowed for every planner execution (seconds)
- memorylimit: the maximum memory allowed for every planner execution (MB)
- hostname: the name of the host on which the experiment was run
- date: the date and time when the experiment was started
Collected benchmark data for each planner execution:
- time: (real) the amount of time spent planning, in seconds
- memory: (real) the amount of memory spent planning, in MB. Note: this may be inaccurate since memory is often freed in a lazy fashion
- solved: (boolean) flag indicating whether the planner found a solution. Note: the solution can be approximate
- approximate solution: (boolean) flag indicating whether the found solution is approximate (does not reach the goal, but moves towards it)
- solution difference: (real) if the solution is approximate, this is the distance from the end-point of the found approximate solution to the actual goal
- solution length: (real) the length of the found solution
- solution smoothness: (real) the smoothness of the found solution (the closer to 0, the smoother the path is)
- solution clearance: (real) the clearance of the found solution (the higher the value, the larger the distance to invalid regions)
- solution segments: (integer) the number of segments on the solution path
- correct solution: (boolean) flag indicating whether the found solution is correct (a separate check is conducted). This should always be true.
- correct solution strict: (boolean) flag indicating whether the found solution is correct when checked at a finer resolution than the planner used when validating motion segments. If this is sometimes false it means that the used state validation resolution is too high (only applies when using ompl::base::DiscreteMotionValidator).
- simplification time: (real) the time spend simplifying the solution path, in seconds
- simplified solution length: (real) the length of the found solution after simplification
- simplified solution smoothness: (real) the smoothness of the found solution after simplification (the closer to 0, the smoother the path is)
- simplified solution clearance: (real) the clearance of the found solution after simplification (the higher the value, the larger the distance to invalid regions)
- simplified solution segments: (integer) the number of segments on solution path after simplification
- simplified correct solution: (boolean) flag indicating whether the found solution is correct after simplification. This should always be true.
- simplified correct solution strict: (boolean) flag indicating whether the found solution is correct after simplification, when checked at a finer resolution.
- graph states: (integer) the number of states in the constructed graph
- graph motions: (integer) the number of edges (motions) in the constructed graph
- valid segment fraction: (real) the fraction of segments that turned out to be valid (using ompl::base::MotionValidator) out of all the segments that were checked for validity
- more planner-specific properties
Planning algorithms can also register callback functions that the Benchmark class will use to measure progress properties at regular intervals during a run of the planning algorithm. Currently only RRT* uses this functionality. The RRT* constructor registers, among others, a function that returns the cost of the best path found so far:
With the Benchmark class one can thus measure how the cost is decreasing over time. The ompl_benchmark_statistics.py script will automatically generate plots of progress properties as a function of time.
Sample benchmark results
Below are sample results for running benchmarks for two example problems. See the gallery for visualizations of sample solutions to both problems. The results below were run on a recent model Apple MacBook Pro (2.66 GHz Intel Core i7, 8GB of RAM). It is important to note that none of the planner parameters were tuned; all benchmarks were run with default settings. From these results one cannot draw any firm conclusions about which planner is “better” than some other planner.
These are the PDF files with plots as generated by the ompl_benchmark_statistics.py script:
The plots show comparisons between ompl::geometric::RRTConnect, ompl::geometric::RRT, ompl::geometric::BKPIECE1, ompl::geometric::LBKPIECE1, ompl::geometric::KPIECE1, ompl::geometric::SBL, ompl::geometric::EST, and ompl::geometric::PRM. Each planner is run 500 times with a 10 second time limit for the cubicles problem for each sampling strategy, while for the Twistycool problem each planner is run 50 times with a 60 second time limit.
For integer and real-valued measurements the script will compute box plots. For example, here is the plot for the real-valued attribute time for the cubicles environment:
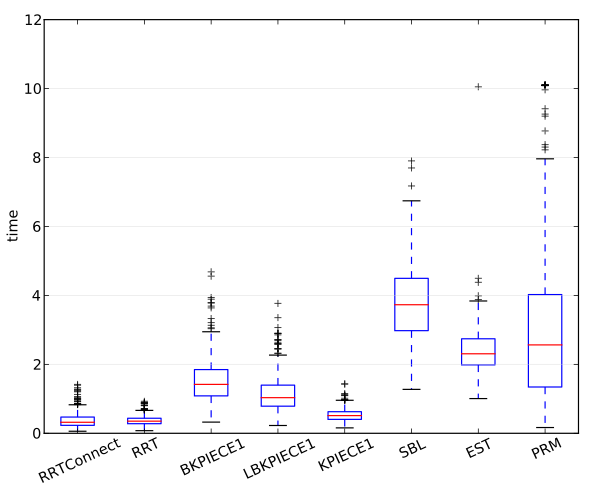
For boolean measurements the script will create bar charts with the percentage of true values. For example, here is the plot for the boolean attribute solved for the Twistycool environment, a much harder problem:
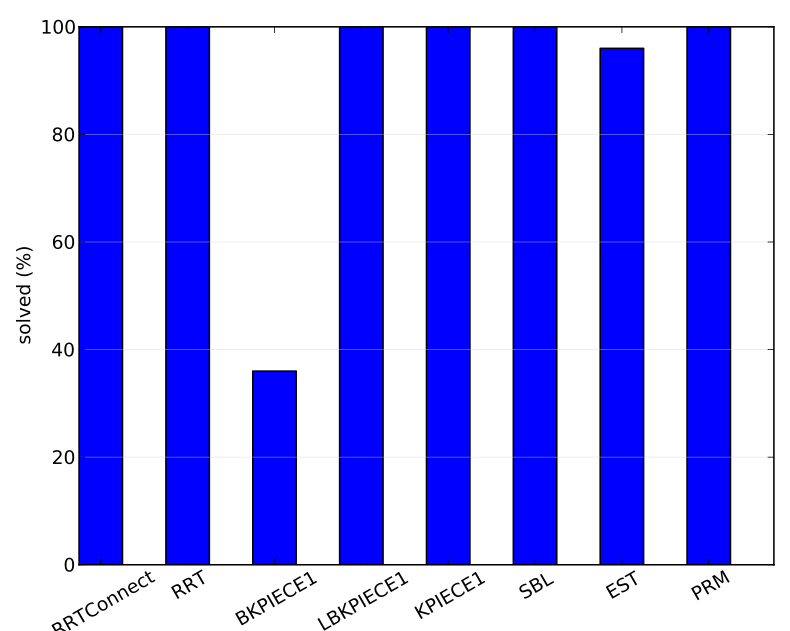
Whenever measurements are not always available for a particular attribute, the columns for each planner are labeled with the number of runs for which no data was available. For instance, the boolean attribute correct solution is not set if a solution is not found.
The benchmark logfile format
The benchmark log files have a pretty simple structure. Below we have included their syntax in Extended Backus-Naur Form. This may be useful for someone interested in extending other planning libraries with similar logging capabilities (which would be helpful in a direct comparison of the performance of planning libraries). Log files in this format can be parsed by ompl_benchmark_statistics.py (see next section).
Here, EOL denotes a newline character, int denotes an integer, float denotes a floating point number, num denotes an integer or float value and undefined symbols correspond to strings without whitespace characters. The exception is property_name which is a string that can have whitespace characters. It is also assumed that if the log file says there is data for k planners that that really is the case (likewise for the number of run measurements and the optional progress measurements).
The benchmark database schema
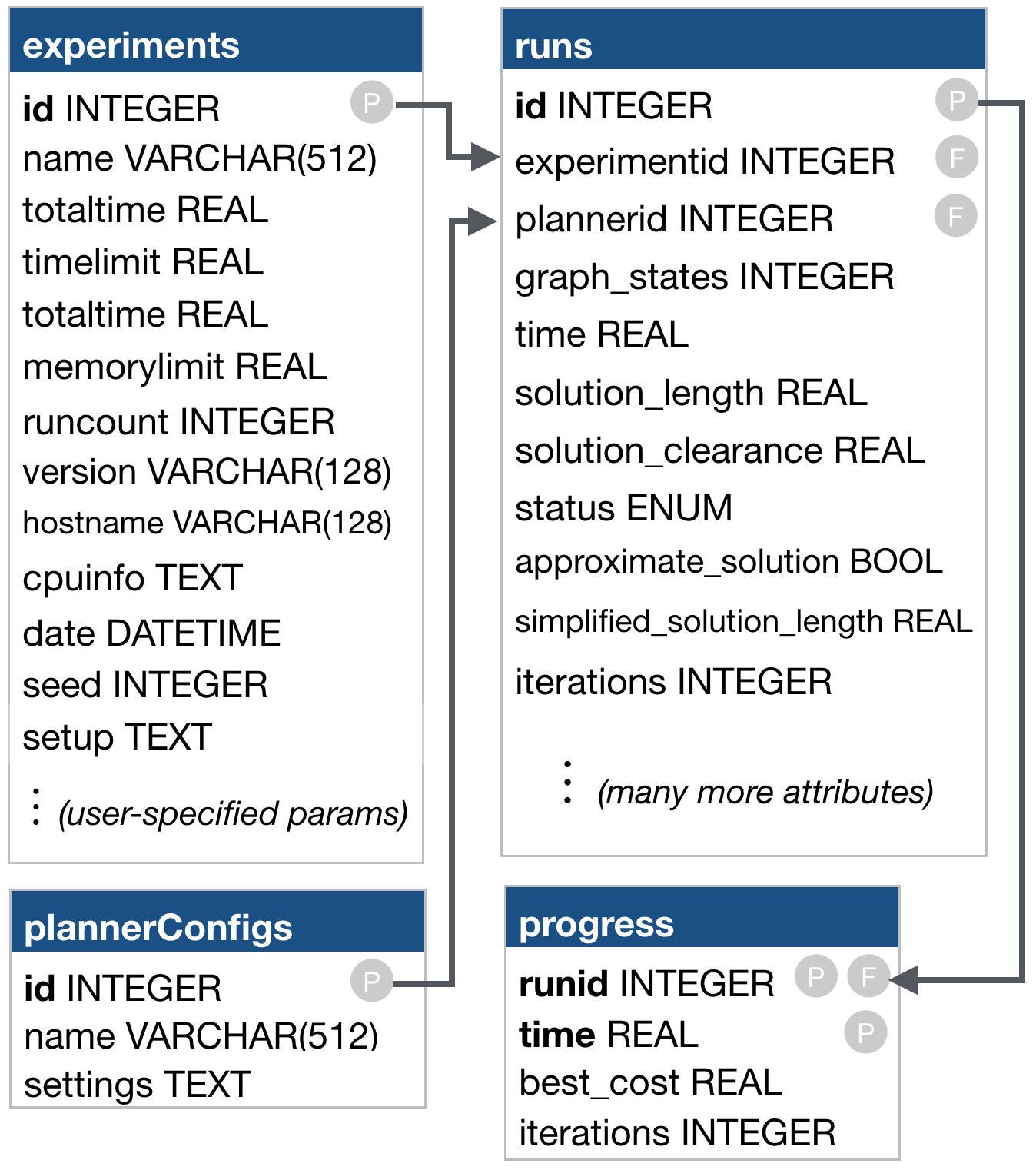
The benchmark database schema
The ompl_benchmark_statistics.py script can produce a series of plots from a database of benchmark results, but in many cases you may want to produce your own custom plots. For this it useful to understand the schema used for the database. There are five tables in a benchmark database:
- experiments. This table contains the following information:
- id: an ID used in the runs table to denote that a run was part of a given experiment.
- name: name of the experiment.
- totaltime: total duration of the experiment in seconds.
- timelimit: time limit for each individual run in seconds.
- memorylimit: memory limit for each individual run in MB.
- runcount: the number of times each planner configuration was run.
- version: the version of OMPL that was used.
- hostname: the host name of the machine on which the experiment was performed.
- cpuinfo: CPU information about the machine on which the experiment was performed.
- date: the date on which the experiment was performed.
- seed: the random seed used.
- setup: a string containing a “print-out” of all the settings of the SimpleSetup object used during benchmarking.
- plannerConfigs. There are a number of planner types (such as PRM and RRT), but each planner can typically be configured with a number of parameters. A planner configuration refers to a planner type with specific parameter settings. The plannerConfigs table contains the following information:
- id: an ID used in the runs table to denote that a given planner configuration was used for a run.
- name: the name of the configuration. This can be just the planner name, but when using different parameter settings of the same planner it is essential to use more specific names.
- settings: a string containing a “print-out” of all the settings of the planner.
- enums: This table contains description of enumerate types that are measured during benchmarking. By default there is only one such such type defined: ompl::base::PlannerStatus. The table contains the following information:
- name: name of the enumerate type (e.g., “status”).
- value: numerical value used in the runs
- description: text description of each value (e.g. “Exact solution,” “Approximate solution,” “Timeout,” etc.)
- runs. The runs table contains information for every run in every experiment. Each run is identified by the following fields:
- id: ID of the run
- experimentid: ID of the experiment to which this run belonged.
- plannerid: ID of the planner configuration used for this run.
- progress. Some planners (such as RRT*) can also periodically report properties during a run. This can be useful to analyze the convergence or growth rate. The progress table contains the following information:
- runid: the ID of the run for which progress data was tracked.
- time: the time (in sec.) at which the property was measured.
- iterations: the number of iterations.
- collision_checks: the number of collision checks (or, more precisely, the number state validator calls).
- best_cost: the cost of the best solution found so far.
Using SQL queries one can easily select a subset of the data or compute joins of tables. Consider the following snippet of R code:
For a small database with 1 experiment and 5 planner configurations we then obtain the following two plots:
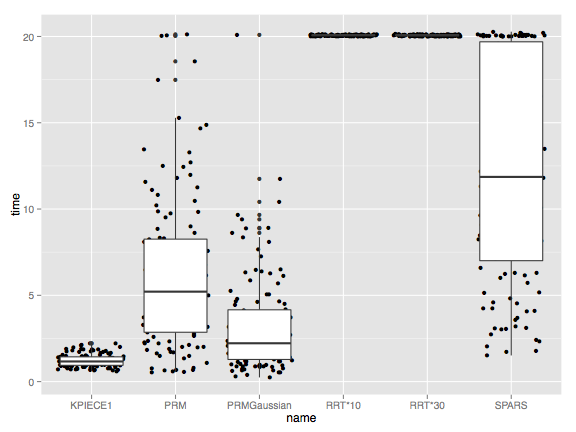
Time to find a solution. Note that that RRT* does not terminate because it keeps trying to find a more optimal solution.
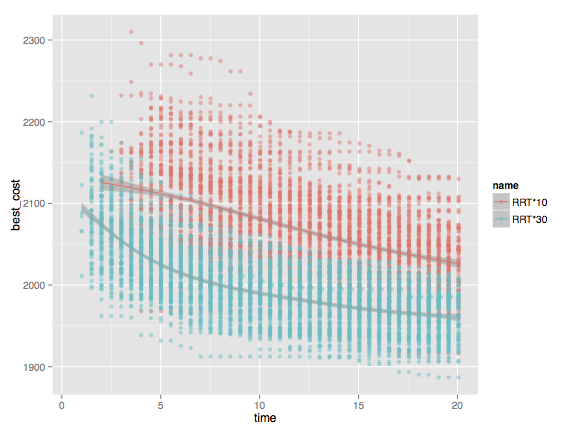
Length of shortest path found after a given number of seconds. Only RRT* currently uses progress properties. Although the variability among individual runs is quite high, one can definitely tell that different parameter settings (for the range in this case) lead to statistically significant different behavior.
- Note
- Similar code is used for Planner Arena, a web site for interactive visualization of benchmark databases. The Planner Arena code is part of the OMPL source. Instructions for running Planner Arena locally can be found here.