Extended support to optimal planners: CForest + tree pruning
Javier V Gomez
The OMPL has extended its capabilities regarding optimal planning by implementing the CForest parallelization framework and the RRTstar (RRT*) tree pruning option. Both of them work under the same assumptions:
- The configuration space obeys the triangle inequality.
- There exists an admissible heuristic (for the optimization objective!).
We are looking forward you to use these new features and hear your feedback!
RRTstar tree prunning
Pruning was implemented as a tool for the CForest parallelization framework. However, as it is a useful tool (that other RRT* versions also use) we decided to implement it as an independent feature.
Every time RRT* finds a new, better solution, it is possible to discard those nodes of the tree that surely will not lead to a better solution. Moreover, it is also possible to immediately discard those samples that will not be useful, thus saving tons of time.
Therefore, the search tree will focus on those zones in which the solution can be only improved. This implies a speedup in the convergence rate since the probability of sampling states close to the optimal path is increased.
How to use it?
To use this feature just use the RRTstar planner as always and add a call to its setPrune() method with a true argument.
Results
These two images correspond to benchmarks carried out in the alpha 1.5 puzzle and with the kinematic chain problem using 10 links, respectively.
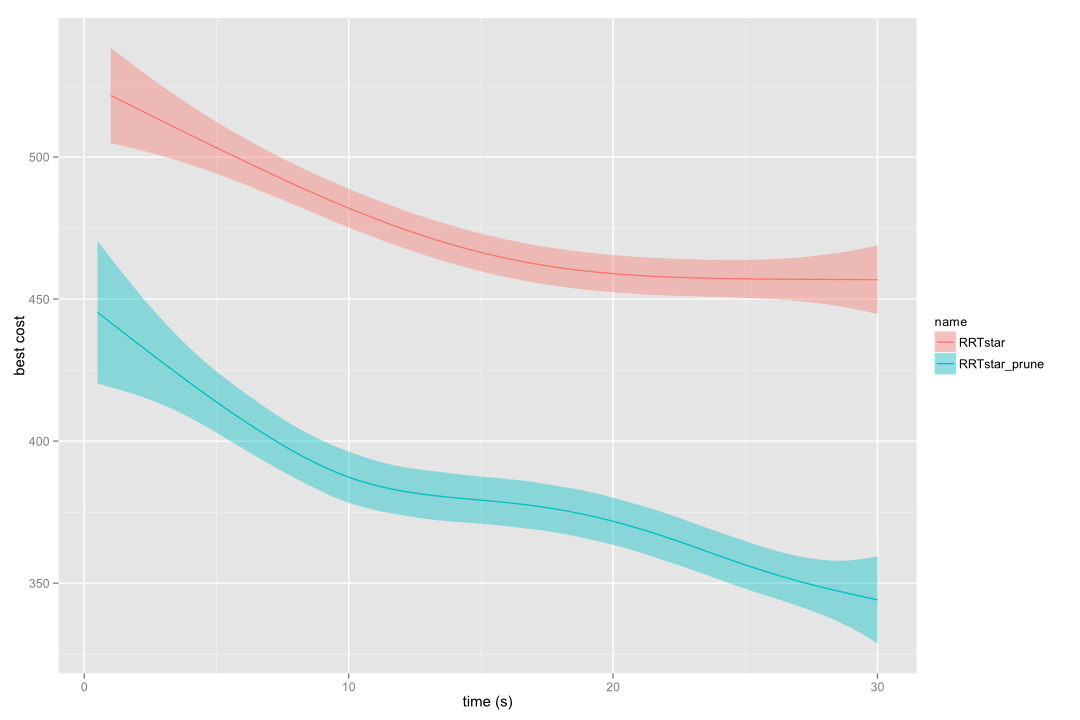
RRT* vs pruned RRT* in alpha 1.5 puzzle
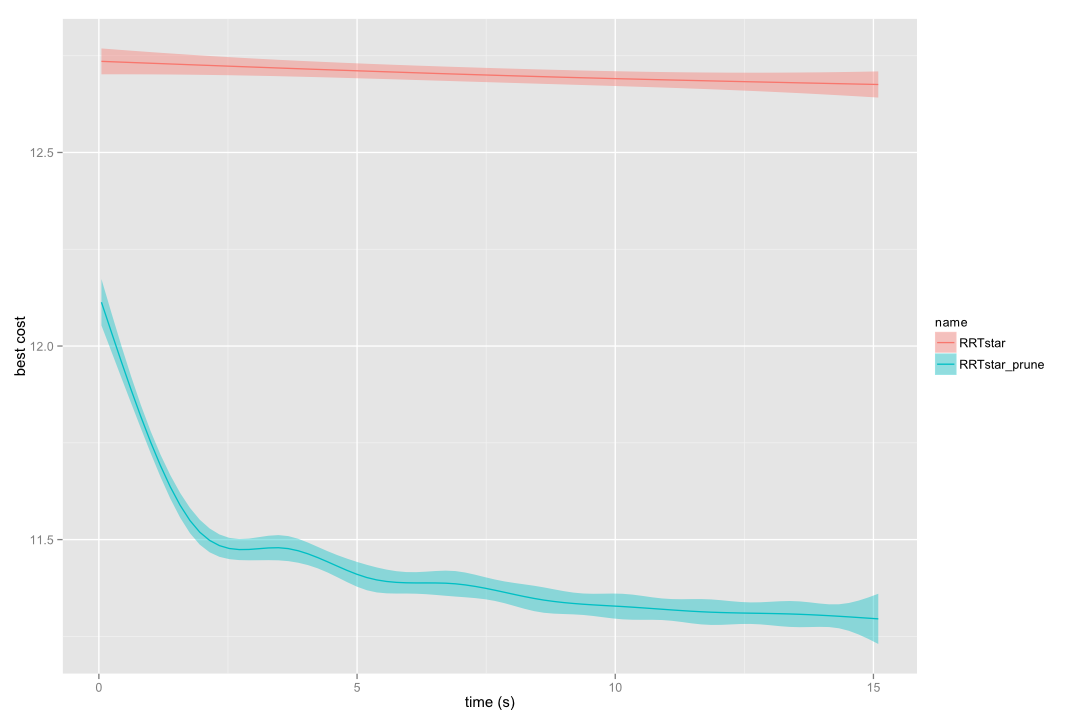
RRT* vs pruned RRT* in a 10-links kinematic chain
We highly recommend to benchmark whether the prune utility is interesting for the problem you aim to solve. We never found standard RRT* to outperform pruned RRT*, however for some specific (usually easy to solve) problems the gain is too little. For the general case, the convergence towards the optimal path is greatly improved.
CForest parallelization framework
Now, let’s move to the next level. What if instead of one single random tree we grow many of them in parallel? Probability of finding a better solution increases. But now, going a bit further, what if we allow the trees to communicate each other, so they share the best paths found so far? Then, we would be thinking in the CForest parallelization framework.
This very simple, yet powerful idea is already implemented in OMPL! CForest expands many trees in different threads (running underlying planner instances of regular planning algorithms, such RRT*). Every time a new, better solution is found by one of the trees, it is shared to all other trees. Also, trees are pruned according to the new shared path.
How to use it?
CForest has been included as a new geometric planner, in order to make it easier for the user. Create it as any other planner. By default, it will expand as many trees as available cores in your machine. However, you can configure it to any number of threads and also you can decide if you want to prune the trees.
New demos have been included into OMPL that show how to use and configure it.
Currently, RRT* is the only underlying planner for the CForest available in OMPL. However, any incremental, optimal planning algorithm could be intergrated into CForest. Check the code documentation to learn how.
Results
CForest implies a huge performance improvement in most of the problems. The convergence towards a path with optimal cost is much faster, as the following images show, running CForest with 4, 8 and 16 trees (in independent CPUs):

CForest vs RRT* in alpha 1.5 puzzle
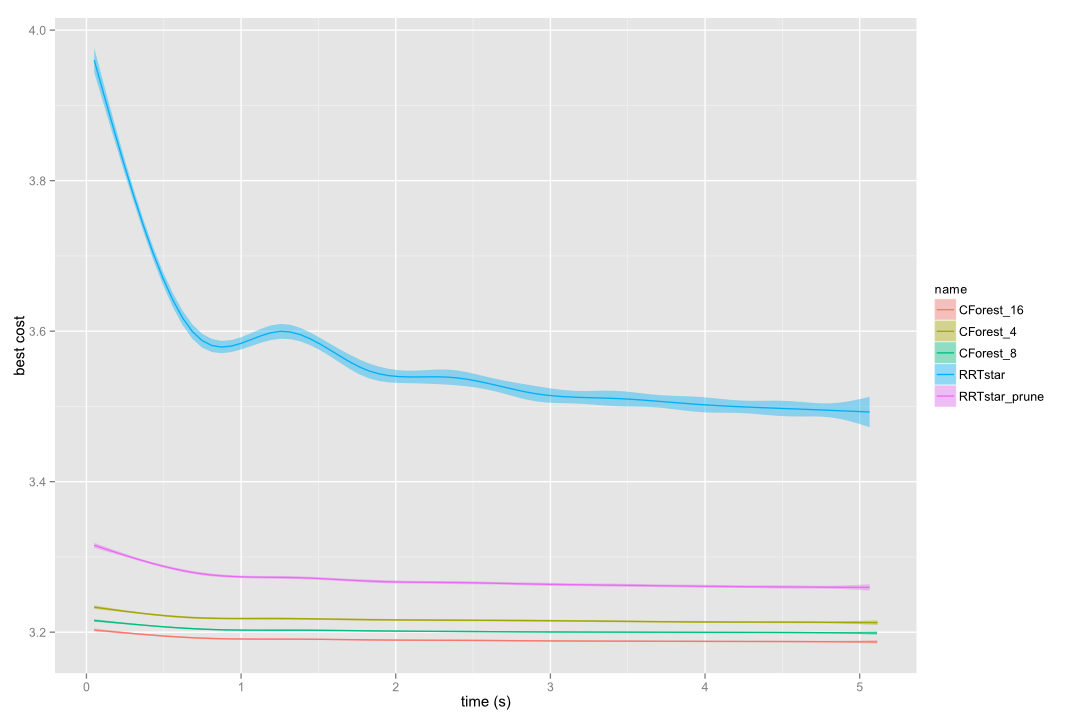
CForest vs RRT* in the circles grid benchmark
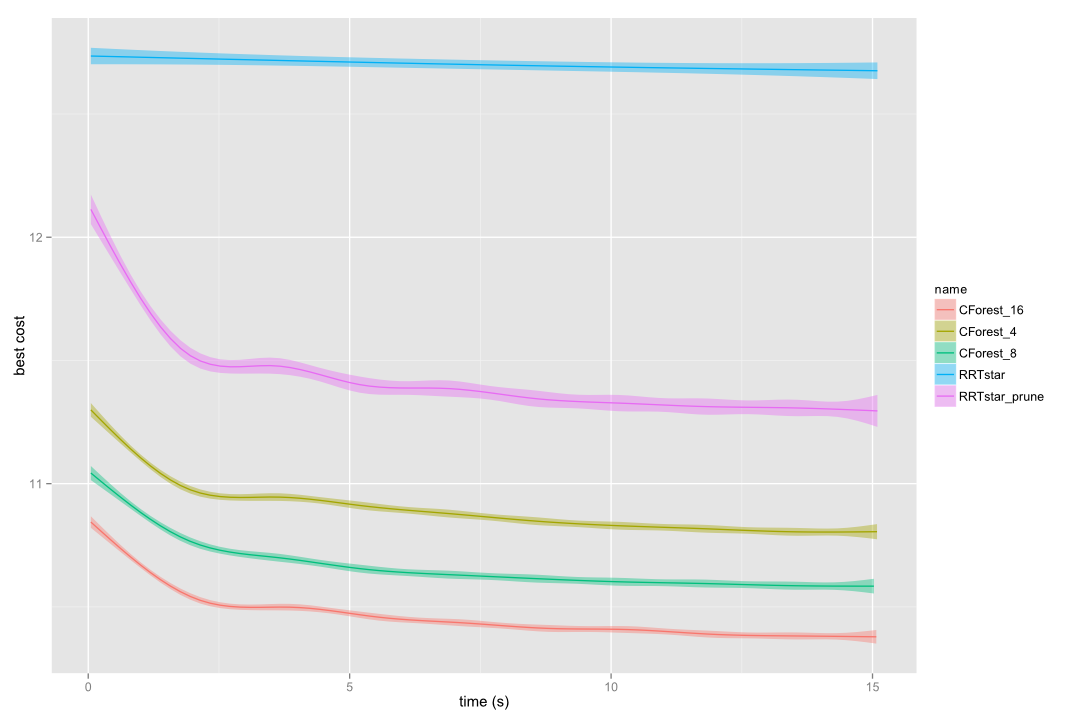
CForest vs RRT* in a 10-links kinematic chain
Only 1 cpu available?
Do not worry! Take a look at the following picture. There, CForest expanding 2, 4 and 8 threads in a single core is being compared to standard RRT* and pruned RRT* pruned in the alpha 1.5 puzzle. Even this way, we are getting an important speedup! This is what CForest authors called sequential CForest. In this case, we built it implicitly as each tree is running in a separate thread, but all threads are running in the same CPU.
Be careful, if you increment the number of threads too much, it could happen that CForest introduces too much overhead and it can result in a performance worsening.
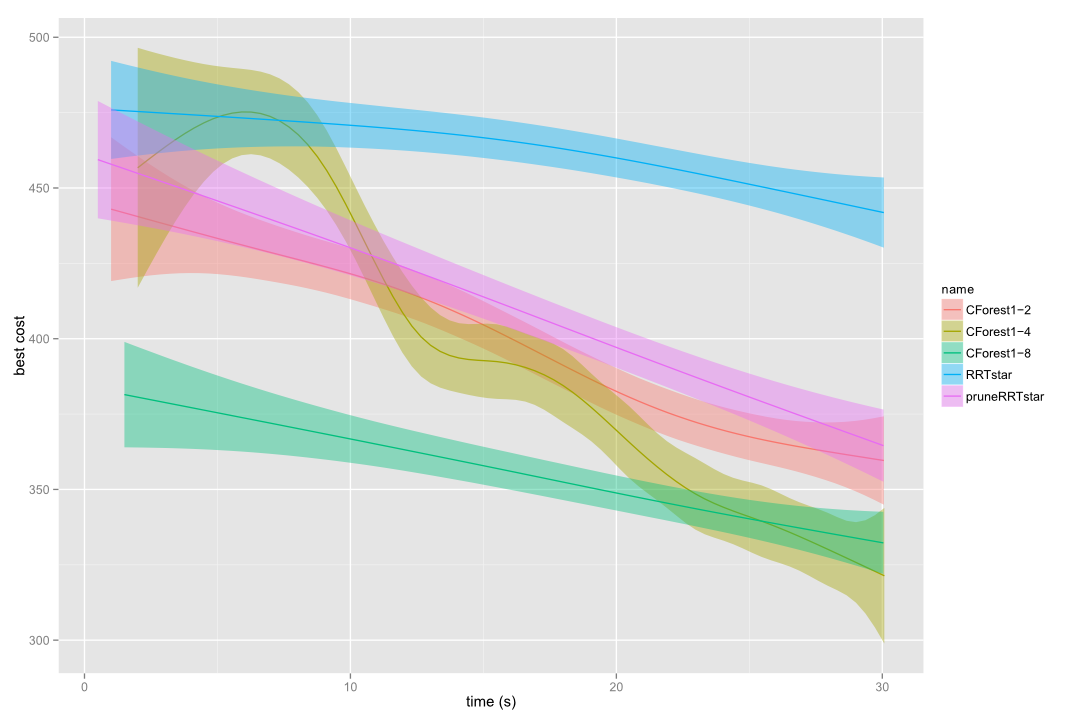
Single core CForest vs RRT* in a alpha 1.5 puzzle
Important Notes
CForest is designed for single-query, shortest path planning problems. This does not restrict it to path length optimization. Optimizing path execution time or energy consumed can be treated as shortest path length.
If you want to push CForest to its limits, please read carefully the API documentation and the optimal planning section. There are many differences with the paper version that you could take into account. We aimed to keep the code as simple as possible.