Table of Contents
CForest was proposed by M. Otte and N. Correll in this paper.
The main idea behind CForest is that many trees are built in parallel between the same start and goal states. The key concepts of CForest are:
- Every time a tree finds a better solution, it is shared with all other trees so that all trees have the best solution found so far.
- Trees are expanded into regions that are known to be beneficial. Samples that cannot lead to a better solution are immediately discarded.
- Trees are pruned every time a better solution is found. Those states in the tree that do not help to find a better solution are removed from the tree.
CForest is designed to be used with any random tree algorithm under the following assumptions:
- The search tree has almost sure convergence to the optimal solution.
- The configuration space obeys the triangle inequality. That is, there exists an admissible heuristic.
CForest in OMPL
CForest has been included into OMPL as a new optimizing planner called ompl::geometric::CForest.
- Note
- CForest is designed to optimize path lengths. In OMPL, it is possible to optimize with respect to an arbitrary optimization objective. Therefore, the requirements for CForest in OMPL are not for the state space but for the optimization objective. It requires an optimization objective with an admissible heuristic. Since this is complex to check, a warning is shown if the state space is not a metric space (although this does not mean that the optimization objective is not valid to be used with CForest).
Currently RRT* (ompl::geometric::RRTstar) is the only underlying planner available, since it is the only single-query, incremental, asymptotically optimal planning algorithm implemented in OMPL.
The CForest planner is responsible for coordinating different trees and sharing the solutions found. Path sharing is done through a specific CForest state sampler (ompl::base::CForestStateSampler). This sampler wraps around the default sampler associated with the state space CForest is planning in. The sampler wrapper will usually just pass through any calls to sampling methods, but when a thread finds a new best solution, subsequent calls to the sampling methods will return subsequent states along the best found path. This is done for each thread except the one that found the best solution.
From the user perspective, CForest can be used as any other planning algorithm:
By default, it will use as many RRT* instances as cores available. The number of instances and the underlying planner can be modified calling the addPlannerInstances<T>() method:
The call addPlannerInstances<T>() will check the PlannerSpecs of the planner type given. CForest only supports all those planners with the canReportIntermediateSolutions spec true. Otherwise, the following warning will appear during execution (test with PRM*):**
Warning: PRMstar cannot report intermediate solutions, not added as CForest planner.
at line 100 in ompl/geometric/planners/cforest/CForest.h
If not valid planners are added by the user, two instances of RRTstar will be automatically set.
Alternatively, only the number of threads could be specified and the default underlying planner (RRT*) will be chosen. This is specially useful when using the planner with a benchmark configuration file:
- Note
- No Python bindings are available for this planner due to its multi-threaded implementation.
Main differences with the paper version
When implementing CForest, the focus was to modify the underlying planner as little as possible. Although the main idea of CForest remains, the actual implementation differs from the one proposed in the paper:
- No message passing is used. Instead, shared memory and std::threads are employed.
- The paper creates two different versions: sequential (many trees expanding in the same CPU) and parallel (1 tree per CPU). Since std::threads are used, the trees/CPU division is done by the scheduler.
- In the paper, shared states are treated in a slightly different way than randomly sampled states. Due to the CForestStateSampler encapsulation, all states are treated the same way. Under some circumstances shared states are not included in other trees. However, tests showed that this does not have a high impact on performance.
- Sampling bounds are not explicitly set. When samples are created, we check whether they can lead to a better solution.
- Start and goal states are not included in the shared paths in order to keep code simpler.
- Before pruning a tree, it is checked how many states would be removed. If the ratio of the size of the new tree size to the size of the old tree is not small enough, pruning will not be carried out. This reduces the amortized cost of having to rebuild NearestNeighbors datastructures when states are pruned.
- Note
- Despite all these differences, the CForest implementation greatly improves the performance of the underlying planner. However, an implementation closer to the one described in the paper could improve the performance. Please, take that into account if you plan to compare your algorithm against CForest.
Example
- Circle Grid benchmark. Benchmarks the performance of CForest against RRT* in a specific 2D circle grid problem.
Results
CForest produces many interesting results. All these results are obtained with the alpha 1.5 puzzle benchmark configuration included in OMPL.app. The following figure shows the results of running CForest in 2 and 16 threads in a 16-core machine. Also, the standard RRT* and the pruned version are included in the benchmark.
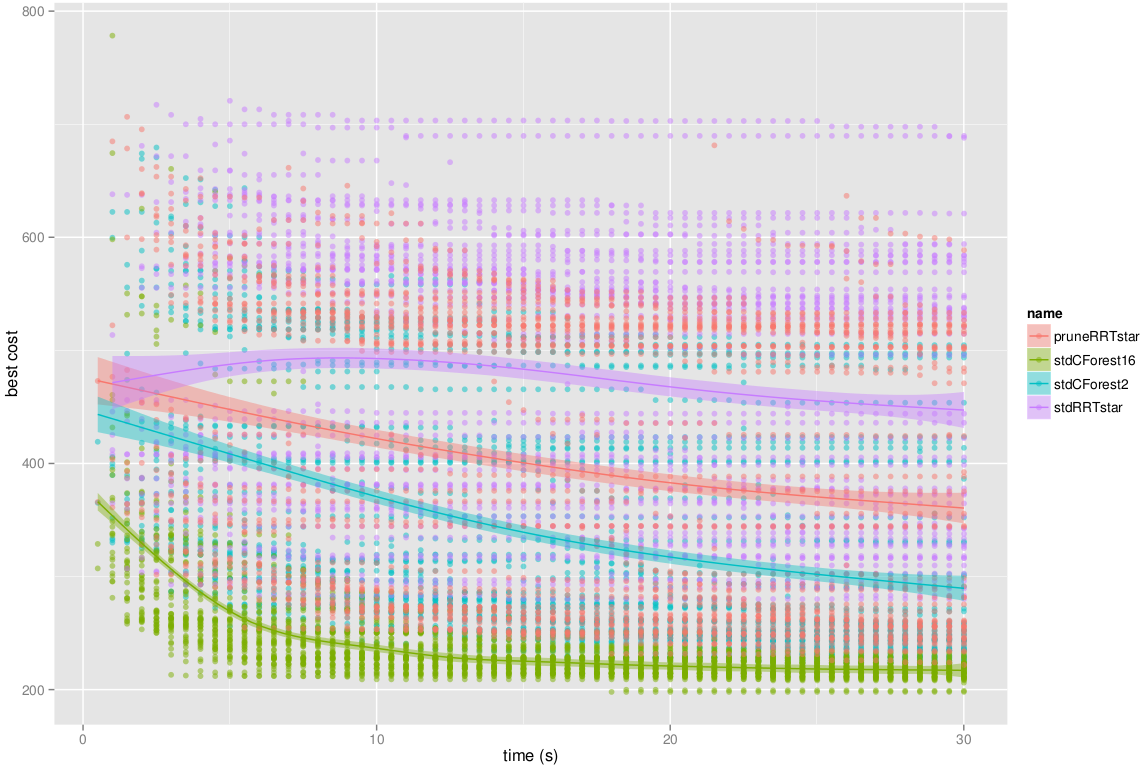
Best cost evolution through time. CForest converges faster towards the minimum cost (optimal solution) as the threads are increased. Pruned RRT* also improves the standard RRT*.
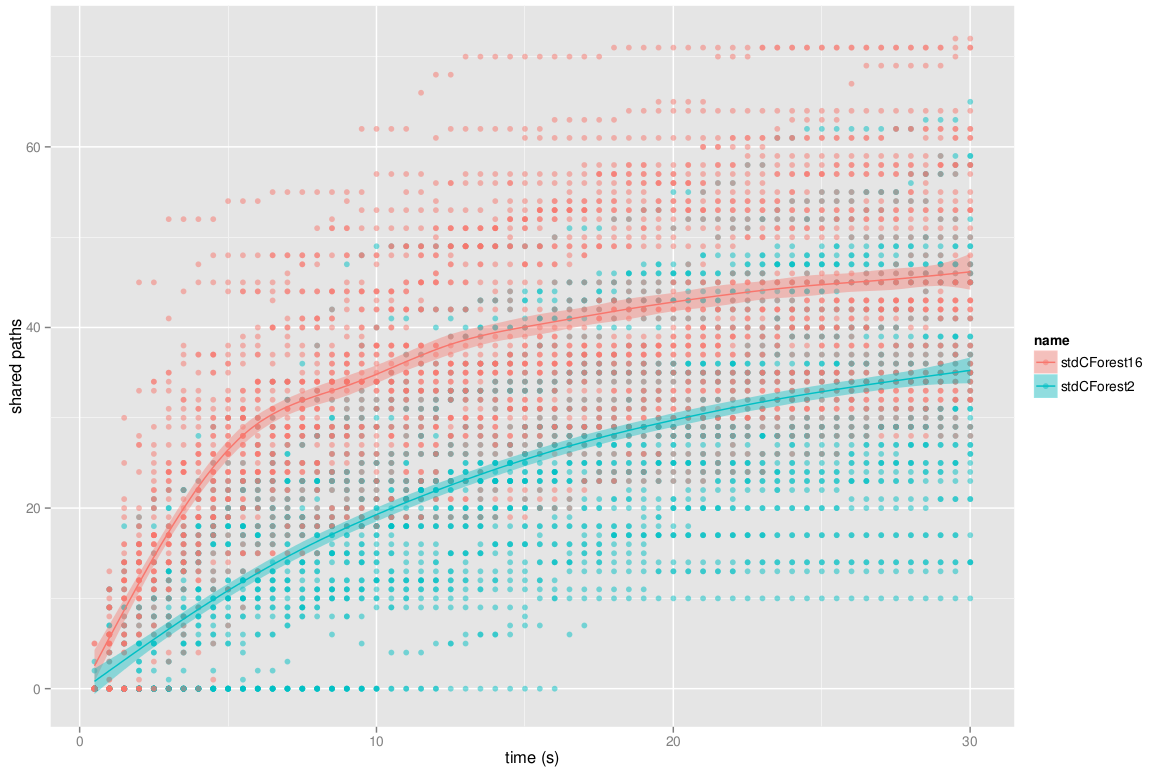
Number of paths shared by CForest.
Another interesting experiment is to run CForest with pruning deactivated and compare it to the standard CForest:
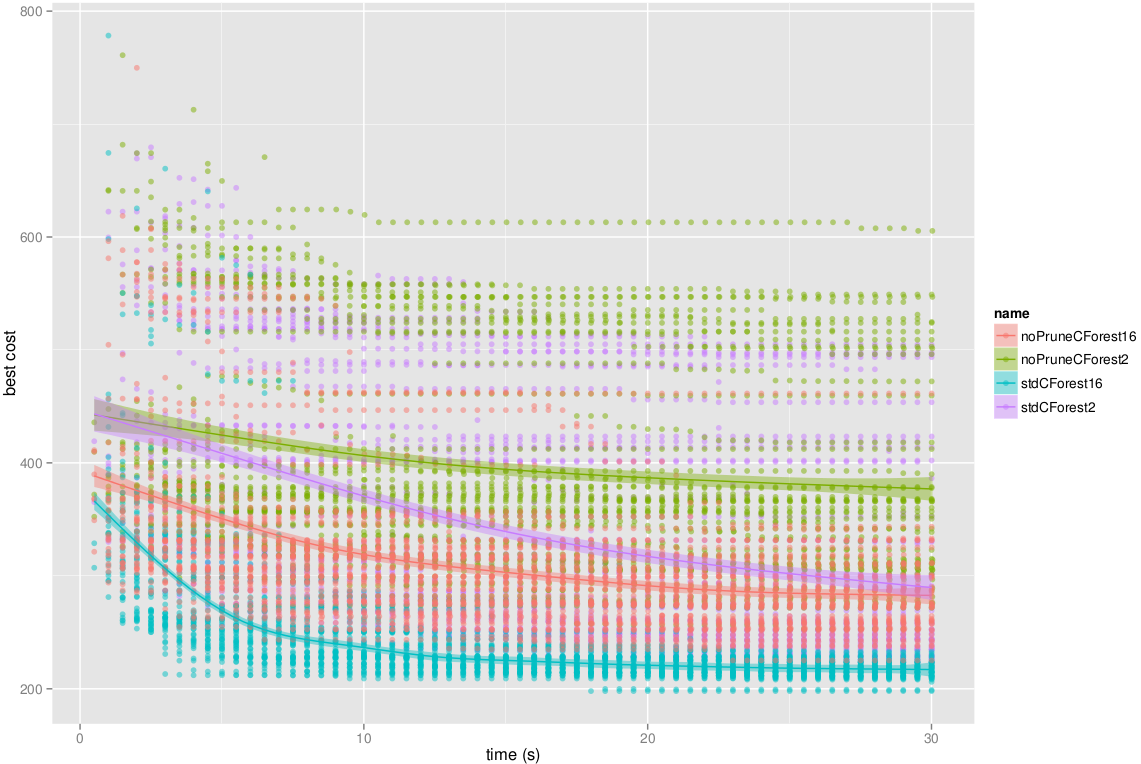
Best cost evolution through time. Not pruning trees affects negatively on the convergence. However, it still improves the standard RRT.
In case you only have one core available, CForest still improves the RRTstar performance! The following figure shows that using CForest in one single core but with many threads (in the picture 4 and 8) also improves the convergence rate against standard RRT* and its pruned version, reaching lower cost solutions in much less time.
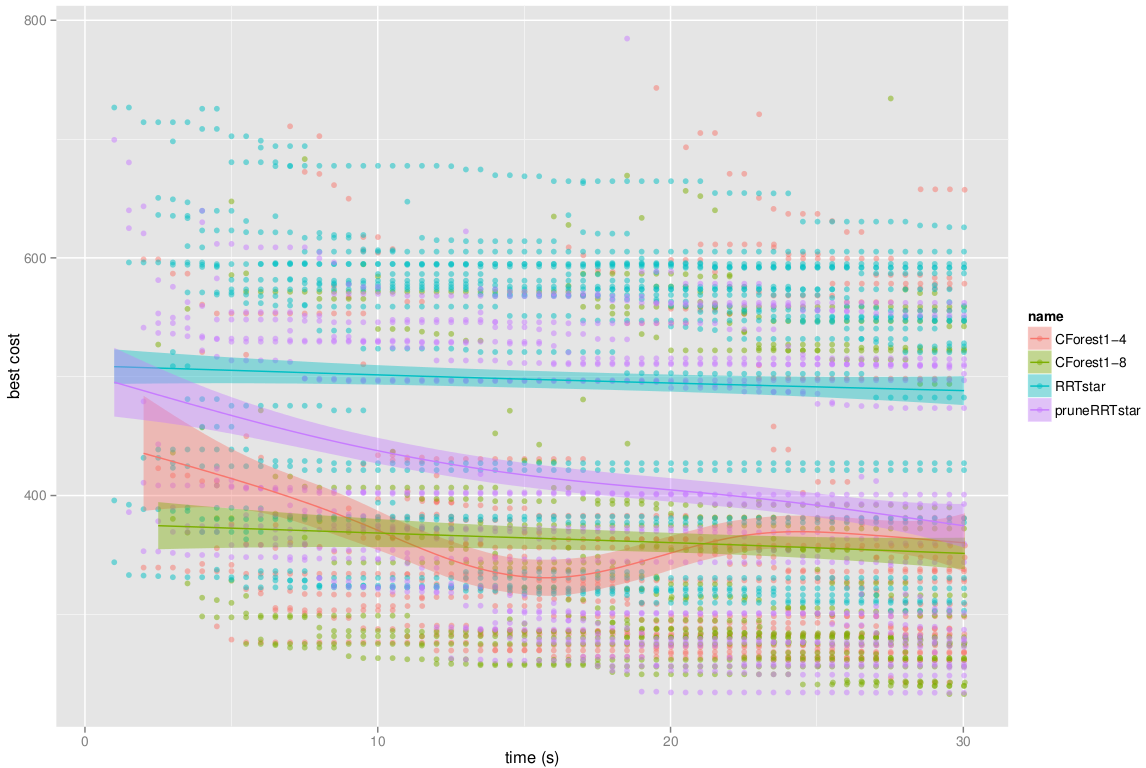
Best cost evolution through time Sequential version of the CForest: many threads working in the same core.
Advanced information
Design and implementation details
The CForest planner comes with its own state sampler ompl::base::CForestStateSampler and its own state space ompl::base::CForestStateSpaceWrapper. They are completely transparent to the user as the ompl::geometric::CForest handles the creation of these.
CForest operates on the user-specified ompl::base::SpaceInformation. However, CForest instantiates the underlying planners with an individual SpaceInformation instance for each planner, containing an instance of a CForestStateSpaceWrapper. When the underlying planner allocates the StateSampler, CForestStateSpaceWrapper creates an instance of a CForestStateSampler which wraps the user-specified state sampler (or the default sampler if none was provided). This design is summarized in the following schema:
Whenever a planner calls SpaceInformation::allocStateSampler() (or allocDefaultStateSampler()), CForestStateSpaceWrapper allocates a CForestStateSampler which creates and wraps the provided StateSampler (or default if none was specified).
Therefore, CForest tracks the creation of the planners but, thanks to the CForestStateSpaceWrapper, it also tracks the creation of the state samplers. This allows CForest to maintain a planner-sampler correspondence required to shared paths between trees.
This new state sampler allows given states (as opposed to random states) to be sampled. Therefore, when a new, better solution is found, CForest shares the states of the new solution to all samplers. CForestStateSampler will sample these states. Once states are sampled, it will continue sampling states according to its underlying state sampler.
Limitations
- CForest is designed to solve single-query, shortest path planning problems. Therefore, not all the ompl::base::OptimizationObjective instantiations are valid. The cost metric has to obey the triangle inequality. It is important to note that shortest path planning does not mean that only the path length can be optimized. Other metrics could be specified: time, energy, etc. However, clearance or smoothness optimization are examples of non-valid optimization objectives.
- Whenever the tree is pruned, the states are removed from the
NearestNeighborsdata structure. However, current implementation does not remove pruned states until the planner instance is destroyed. This is specific for the underlying planner implementations but this is the most efficient way in terms of computation time.
Make your planner CForest-compatible
If you have implemented an incremental, optimizing planner in OMPL and want make it compatible with CForest, there are few modifications you should carry out on your planner.
There are three main components that should be included:
- CForest activation and configuration.
- Path sharing.
- Tree pruning.
CForest activation and configuration
Firstly, if working under CForest, the corresponding callback for sharing intermediate solutions must be set. Also, a check should be included to figure out if the pruning would cause some errors. Therefore, in the solve() function, you need to add the following code:
prune_ flag will be set but the user or the CForest framework. This flag manages the code related to tree pruning and early state rejection. If intermediateSolutionCallback is false, then the path sharing code will not be executed.
Since all CForest threads share the same PlannerTerminationCondition, it is recommended to include the following call once the main loop of the solve() function has finished:
This is particularly useful when one of the threads breaks out the loop but the ptc will still evaluate to true. For instance, this happens in RRTstar every time a cost threshold is set.
- Note
- CForest can be used without pruning. In this case, the
prune_flag is activated only if the ompl::geometricCForest::setPrune() method was called with a true argument (it is activated by default). Tree pruning in RRTstar can be used as an independent feature.
Path sharing
As CForest is designed to use incremental, optimizing planners, it is assumed you will have a flag in your code to indicate when a new, better path has been found and a pointer to the motion which contains the last state (goal) of the solution. Therefore, at the end of the main loop within the solve function, you should add a code similar to the following:
- Note
- The spath vector has to contain the states of the solution from the goal to the start (in this specific order).
In this case, the goal and start states are not being included since it is usually harder to deal with those two states. Code simplicity prevails, but this really depends on the underlying planner used together with CForest.
It is likely to share more than one path in which one or more states are modified. This would imply that the tree and solution path would have repeated states. To avoid this, add the following code within the solve() method just after sampling a new state:
If a sampled state is repeated it will be discarded and the next iteration of the main loop will start.
Tree pruning
Pruning refers to two different ways of remove states: 1) prune those states already on the tree that do not lead to a better solution and 2) reject those states before adding them to the tree. In both cases, all the modifications are again within the solve() method. Tree main modifications are done:
- Early state rejection Check if random samples can lead to a better solution (cost used: heuristic from start to state + heuristic from state to goal)
- State rejection**Most of the states satisfy 1., but once they are wired into the tree, they cannot lead to a better solution (cost used: cost to go from start to state + heuristic from state to goal) (early state rejection).
- **Tree pruning If a new, better solution is found, the pruning threshold will be decreased, therefore prune the states of the tree so that all those states which higher cost than the current best cost are removed.
All these modifications are included in the following code example:
- Note
- You should implement the
pruneTree()function for your code. Most probably, the available RRTstar::pruneTree() method would be directly applicable. It is possible to use CForest without this method. However, it is highly recommended to at least include the modifications 1 & 2 about state rejection.
For a complete example of how to make these modifications, it is recommended to analyze the ompl::geometric::RRTstar::solve() method.